Буква за стандартно отклонение. Изчислява се средната серийна грешка на извадката
За да се изчисли просто геометричната средна, се използва формулата:
геометрична претеглена
За да се определи геометричната претеглена средна стойност, се използва формулата:
Средните диаметри на колела, тръби, средните страни на квадратите се определят с помощта на средния квадрат.
RMS стойностите се използват за изчисляване на някои показатели, като коефициента на вариация, който характеризира ритъма на продукцията. Тук стандартното отклонение от планираната продукция за определен период се определя по следната формула:
Тези стойности характеризират точно промяната в икономическите показатели спрямо тяхната базова стойност, взета в нейната средна стойност.
Квадратично просто
Средният квадрат просто се изчислява по формулата:

Квадратично претеглено
Претегленият среден квадрат е:

22. Абсолютните мерки за вариация включват:
диапазон на вариации
средно линейно отклонение
дисперсия
стандартно отклонение
Диапазон на вариация (r)
Вариация на обхватае разликата между максималната и минималната стойност на атрибута
Той показва границите, в които се променя стойността на атрибута в изследваната популация.
Трудовият опит на петима кандидати на предишната работа е: 2,3,4,7 и 9 години. Решение: диапазон на вариация = 9 - 2 = 7 години.
За обобщена характеристика на разликите в стойностите на атрибута, средните показатели за вариация се изчисляват въз основа на допустимите отклонения от средноаритметичната стойност. Разликата се приема като отклонение от средната стойност.
В същото време, за да се избегне превръщането в нула сумата от отклоненията на опциите за черта от средната стойност (нулевото свойство на средната стойност), трябва или да се игнорират знаците на отклонението, тоест да се вземе тази сума по модул , или квадрат на стойностите на отклонението
Средно линейно и квадратно отклонение
Средно линейно отклонениее средната аритметична стойност на абсолютните отклонения на отделните стойности на атрибута от средната стойност.
Средното линейно отклонение е просто:
Трудовият опит на петима кандидати на предишната работа е: 2,3,4,7 и 9 години.
В нашия пример: години;
Отговор: 2,4 години.
Средно претеглено линейно отклонениесе отнася за групирани данни:
Средното линейно отклонение, поради своята условност, се използва сравнително рядко на практика (по-специално, за характеризиране на изпълнението на договорните задължения по отношение на еднаквостта на доставката; при анализа на качеството на продукта, като се вземат предвид технологичните характеристики на производството ).
Стандартно отклонение
Най-съвършената характеристика на вариацията е стандартното отклонение, което се нарича стандарт (или стандартно отклонение). Стандартно отклонение() е равно на квадратния корен от средния квадрат на отклоненията на отделните стойности на характеристиката от средноаритметичната:
Стандартното отклонение е просто:


Претегленото стандартно отклонение се прилага за групирани данни:

Между средното квадратично и средното линейно отклонение при условия на нормално разпределение има следната връзка: ~ 1.25.
Стандартното отклонение, като основна абсолютна мярка за вариация, се използва при определяне на стойностите на ординатите на кривата на нормалното разпределение, при изчисления, свързани с организацията на наблюдението на извадката и установяване на точността на характеристиките на пробата, както и при оценка на границите на вариация на даден признак в хомогенна популация.
$X$. Първо, нека си припомним следното определение:
Определение 1
Население-- набор от произволно избрани обекти от даден тип, върху които се правят наблюдения с цел получаване на конкретни стойности на произволна променлива, извършени при непроменени условия при изследване на една произволна променлива от даден тип.
Определение 2
Обща дисперсия-- средноаритметичната стойност на квадратните отклонения на стойностите на варианта на генералната съвкупност от средната им стойност.
Нека стойностите на варианта $x_1,\ x_2,\dots ,x_k$ имат съответно честотите $n_1,\ n_2,\dots ,n_k$. Тогава общата дисперсия се изчислява по формулата:
Нека разгледаме специален случай. Нека всички варианти $x_1,\ x_2,\dots ,x_k$ са различни. В този случай $n_1,\ n_2,\dots ,n_k=1$. Получаваме, че в този случай общата дисперсия се изчислява по формулата:
С тази концепция е свързана и концепцията за общото стандартно отклонение.
Определение 3
Общо стандартно отклонение
\[(\sigma )_r=\sqrt(D_r)\]
Дисперсия на извадката
Нека ни бъде даден примерен набор по отношение на произволна променлива $X$. Първо, нека си припомним следното определение:
Определение 4
Извадка популация-- част от избраните обекти от общата съвкупност.
Определение 5
Дисперсия на извадката-- средноаритметичната стойност на стойностите на варианта на извадковата съвкупност.
Нека стойностите на варианта $x_1,\ x_2,\dots ,x_k$ имат съответно честотите $n_1,\ n_2,\dots ,n_k$. Тогава дисперсията на извадката се изчислява по формулата:
Нека разгледаме специален случай. Нека всички варианти $x_1,\ x_2,\dots ,x_k$ са различни. В този случай $n_1,\ n_2,\dots ,n_k=1$. Получаваме, че в този случай дисперсията на извадката се изчислява по формулата:
С тази концепция е свързана и концепцията за стандартно отклонение на извадката.
Определение 6
Извадково стандартно отклонение-- корен квадратен от общата дисперсия:
\[(\sigma )_v=\sqrt(D_v)\]
Коригирана дисперсия
За да се намери коригираната дисперсия $S^2$, е необходимо да се умножи дисперсията на извадката по дроба $\frac(n)(n-1)$, т.е.
Тази концепция се свързва и с концепцията за коригираното стандартно отклонение, което се намира по формулата:
В случай, че стойността на варианта не е дискретна, а представлява интервали, тогава във формулите за изчисляване на общите или извадкови дисперсии, стойността на $x_i$ се приема като стойността на средата на интервала, до който $ x_i.$ принадлежи
Пример за задача за намиране на дисперсията и стандартното отклонение
Пример 1
Извадковата съвкупност се дава от следната таблица за разпределение:
Снимка 1.
Намерете за него дисперсията на извадката, стандартното отклонение на извадката, коригираната дисперсия и коригираното стандартно отклонение.
За да решим този проблем, първо ще направим изчислителна таблица:
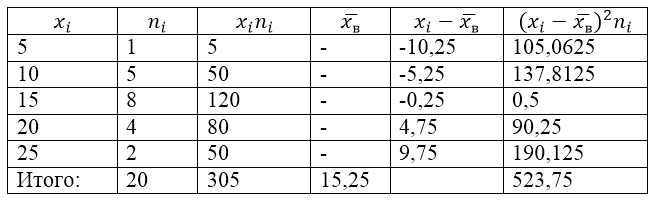
Фигура 2.
Стойността на $\overline(x_v)$ (средна извадка) в таблицата се намира по формулата:
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)\]
\[\overline(x_in)=\frac(\sum\limits^k_(i=1)(x_in_i))(n)=\frac(305)(20)=15,25\]
Намерете извадката дисперсия, като използвате формулата:
Примерно стандартно отклонение:
\[(\sigma )_v=\sqrt(D_v)\приблизително 5,12\]
Коригирана дисперсия:
\[(S^2=\frac(n)(n-1)D)_v=\frac(20)(19)\cdot 26.1875\приблизително 27.57\]
Коригирано стандартно отклонение.
При статистическа проверка на хипотези, при измерване на линейна връзка между случайни величини.
Стандартно отклонение:
Стандартно отклонение(оценка на стандартното отклонение на произволната променлива Под, стени около нас и таван, хспрямо неговото математическо очакване, базирано на безпристрастна оценка на неговата дисперсия):
където - дисперсия; - Подът, стените около нас и таванът, и-ти елемент на проба; - размер на извадката; - средноаритметично на извадката:
Трябва да се отбележи, че и двете оценки са предубедени. В общия случай е невъзможно да се направи безпристрастна оценка. Въпреки това, оценка, базирана на безпристрастна оценка на дисперсията, е последователна.
правило три сигма
правило три сигма() - почти всички стойности на нормално разпределена случайна променлива се намират в интервала. По-строго - с не по-малко от 99,7% сигурност, стойността на нормално разпределена случайна променлива се намира в посочения интервал (при условие, че стойността е вярна, а не е получена в резултат на обработка на извадката).
Ако истинската стойност е неизвестна, тогава трябва да използвате не, а пода, стените около нас и тавана, с. По този начин правилото на трите сигми се превежда в правилото на трите етажа, стените около нас и тавана, с .
Интерпретация на стойността на стандартното отклонение
Голяма стойност на стандартното отклонение показва голямо разпределение на стойностите в представения набор със средната стойност на набора; малка стойност, съответно, показва, че стойностите в набора са групирани около средната стойност.
Например, имаме три набора от числа: (0, 0, 14, 14), (0, 6, 8, 14) и (6, 6, 8, 8). И трите набора имат средни стойности от 7 и стандартни отклонения съответно 7, 5 и 1. Последният набор има малко стандартно отклонение, тъй като стойностите в набора са групирани около средната стойност; първият набор има най-голямата стойност на стандартното отклонение - стойностите в рамките на набора силно се отклоняват от средната стойност.
В общ смисъл стандартното отклонение може да се счита за мярка за несигурност. Например във физиката стандартното отклонение се използва за определяне на грешката на серия от последователни измервания на някаква величина. Тази стойност е много важна за определяне на правдоподобността на изследваното явление в сравнение със стойността, предвидена от теорията: ако средната стойност на измерванията се различава значително от стойностите, предвидени от теорията (голямо стандартно отклонение), тогава получените стойности или методът за получаването им трябва да бъдат проверени отново.
Практическа употреба
На практика стандартното отклонение ви позволява да определите колко стойностите в комплекта могат да се различават от средната стойност.
Климат
Да предположим, че има два града с еднаква средна дневна максимална температура, но единият се намира на брега, а другият е във вътрешността на страната. Известно е, че крайбрежните градове имат много различни дневни максимални температури, по-ниски от тези във вътрешните градове. Следователно стандартното отклонение на максималните дневни температури в крайбрежния град ще бъде по-малко, отколкото във втория град, въпреки факта, че средната стойност на тази стойност е една и съща за тях, което на практика означава, че вероятността максималният въздух температурата на всеки конкретен ден от годината ще бъде по-силна, различна от средната стойност, по-висока за град, разположен вътре в континента.
Спорт
Да приемем, че има няколко футболни отбора, които са класирани по някакъв набор от параметри, например брой отбелязани и допуснати голове, шансове за гол и т.н. Най-вероятно е най-добрият отбор в тази група да има най-добрия стойности в повече параметри. Колкото по-малко е стандартното отклонение на отбора за всеки от представените параметри, толкова по-предвидим е резултатът на отбора, такива отбори са балансирани. От друга страна, отбор с голямо стандартно отклонение трудно може да предвиди резултата, което от своя страна се обяснява с дисбаланс, например силна защита, но слаба атака.
Използването на стандартното отклонение на параметрите на отбора позволява до известна степен да се предвиди резултатът от мача между два отбора, като се оценяват силните и слабите страни на отборите, а оттам и избраните методи на борба.
Технически анализ
Вижте също
литература
| Тази статия се предлага за изтриване.
Обяснение на причините и съответната дискусия можете да намерите на страницата Уикипедия:Бъде изтрит/17 декември 2012 г. |
* Боровиков, В.СТАТИСТИКА. Изкуството на компютърния анализ на данни: За професионалисти / В. Боровиков. - Санкт Петербург. : Петър, 2003. - 688 с. - ISBN 5-272-00078-1.
| Статистически показатели | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| описателен статистика |
|
||||||||||
| Статистически оттегляне и Преглед хипотези |
| ||||||||||
Най-съвършената характеристика на вариацията е стандартното отклонение, което се нарича стандарт (или стандартно отклонение). Стандартно отклонение() е равно на квадратния корен от средния квадрат на отклоненията на стойностите на отделните характеристики от средноаритметичната:
Стандартното отклонение е просто:


Претегленото стандартно отклонение се прилага за групирани данни:

Между средното квадратично и средното линейно отклонение при условия на нормално разпределение има следната връзка: ~ 1.25.
Стандартното отклонение, като основна абсолютна мярка за вариация, се използва при определяне на стойностите на ординатите на кривата на нормалното разпределение, при изчисления, свързани с организацията на наблюдението на извадката и установяване на точността на характеристиките на пробата, както и при оценка на границите на вариация на даден признак в хомогенна популация.
Дисперсия, нейните видове, стандартно отклонение.
Дисперсия на случайна променлива- мярка за разпространението на дадена случайна променлива, т.е. нейното отклонение от математическото очакване. В статистиката често се използва обозначението или. Квадратният корен от дисперсията се нарича стандартно отклонение, стандартно отклонение или стандартно спред.
Пълна дисперсия (σ2) измерва вариацията на даден признак в цялата популация под влиянието на всички фактори, причинили тази вариация. В същото време, благодарение на метода на групиране, е възможно да се изолират и измерват вариациите, дължащи се на групиращия признак, и вариацията, която възниква под влияние на неотчетени фактори.
Междугрупова дисперсия (σ 2 m.gr) характеризира системната вариация, т.е. разликите в величината на изследваната черта, възникващи под влияние на чертата - факторът, лежащ в основата на групирането.
стандартно отклонение(синоними: стандартно отклонение, стандартно отклонение, стандартно отклонение; подобни термини: стандартно отклонение, стандартно разпределение) - в теорията на вероятностите и статистиката, най-често срещаният индикатор за дисперсията на стойностите на произволна променлива спрямо нейното математическо очакване. При ограничени масиви от извадки от стойности вместо математическото очакване се използва средноаритметичната стойност на набора от извадки.
Стандартното отклонение се измерва в единици на самата случайна променлива и се използва при изчисляване на стандартната грешка на средноаритметичната стойност, при конструиране на доверителни интервали, при статистическо тестване на хипотези и при измерване на линейната връзка между случайните променливи. Дефинира се като корен квадратен от дисперсията на произволна променлива.
Стандартно отклонение:

Стандартно отклонение(оценка на стандартното отклонение на произволна променлива хспрямо неговото математическо очакване, базирано на безпристрастна оценка на неговата дисперсия):

къде е дисперсията; — и-ти елемент на проба; — размер на извадката; - средноаритметично на извадката:
![]()
Трябва да се отбележи, че и двете оценки са предубедени. В общия случай е невъзможно да се направи безпристрастна оценка. Въпреки това, оценка, базирана на безпристрастна оценка на дисперсията, е последователна.
Същност, обхват и процедура за определяне на мода и медиана.
В допълнение към средните по степенен закон в статистиката, за относителна характеристика на величината на различен атрибут и вътрешната структура на редовете на разпределение се използват структурни средни стойности, които се представят главно от режим и медиана.
мода- Това е най-разпространеният вариант на поредицата. Модата се използва например при определяне на размера на дрехите, обувките, които са най-търсени сред купувачите. Режимът за дискретна серия е вариантът с най-висока честота. Когато изчислявате режима за серия от вариации на интервала, първо трябва да определите модалния интервал (по максималната честота), а след това стойността на модалната стойност на атрибута по формулата:

- - модна стойност
- - долна граница на модалния интервал
- - стойност на интервала
- - честота на модалния интервал
- - честота на интервала, предхождащ модалния
- - честота на интервала, следващ модала
Медиана -това е стойността на характеристиката, която е в основата на класираната серия и разделя тази серия на две равни по брой части.
За да определите медианата в дискретна серия при наличие на честоти, първо изчислете полусумата от честоти и след това определете каква стойност на варианта пада върху нея. (Ако сортираният ред съдържа нечетен брой характеристики, тогава средното число се изчислява по формулата:
M e \u003d (n (брой характеристики в съвкупността) + 1) / 2,
в случай на четен брой признаци, медианата ще бъде равна на средната стойност на двата признака в средата на реда).
При изчисляване медианиза серия от вариация на интервала първо определете медианния интервал, в който се намира медианата, а след това стойността на медианата съгласно формулата:

- е желаната медиана
- е долната граница на интервала, който съдържа медианата
- - стойност на интервала
- - сборът от честотите или броя на членовете на серията
Сумата от натрупаните честоти на интервалите, предхождащи медианата
- е честотата на медианния интервал
Пример. Намерете режима и медианата.
Решение:
В този пример модалният интервал е във възрастовата група 25-30 години, тъй като този интервал представлява най-високата честота (1054).
Нека изчислим стойността на режима:
Това означава, че модалната възраст на студентите е 27 години.
Изчислете медианата. Медианният интервал е във възрастовата група 25-30 години, тъй като в рамките на този интервал има вариант, който разделя населението на две равни части (Σf i /2 = 3462/2 = 1731). След това заместваме необходимите числови данни във формулата и получаваме стойността на медианата:

Това означава, че едната половина от учениците са на възраст под 27,4 години, а другата половина са на възраст над 27,4 години.
В допълнение към режима и медианата, могат да се използват индикатори като квартили, разделящи класираната серия на 4 равни части, децили- 10 части и процентили - на 100 части.
Концепцията за селективното наблюдение и неговия обхват.
Селективно наблюдениесе прилага при прилагане на непрекъснато наблюдение физически невъзможнопоради голямо количество данни или икономически непрактично. Физическата невъзможност възниква например при изучаване на пътнически потоци, пазарни цени, семейни бюджети. Икономическата нецелесъобразност възниква при оценка на качеството на стоките, свързани с тяхното унищожаване, например дегустация, тестване на тухли за здравина и др.
Избраните за наблюдение статистически единици съставляват извадка или извадка, а целият им масив - генералната съвкупност (GS). В този случай броят на единиците в извадката означава н, и в целия HS - н. Поведение n/Nнаречен относителен размер или пропорция на пробата.
Качеството на резултатите от вземането на проби зависи от представителността на извадката, т.е. колко представителна е тя в HS. За да се гарантира представителността на извадката, е необходимо да се наблюдава принцип на произволен избор на единици, което приема, че включването на HS единица в извадката не може да бъде повлияно от друг фактор освен случайността.
Съществува 4 начина за произволен изборда пробвам:
- Всъщност произволноселекция или „метод на лото“, когато на статистически стойности се присвояват серийни номера, въведени върху определени обекти (например бурета), които след това се смесват в някакъв контейнер (например в торба) и се избират на случаен принцип. На практика този метод се осъществява с помощта на генератор на случайни числа или математически таблици на произволни числа.
- Механичниизбор, според който всеки ( N/n)-та стойност на генералната съвкупност. Например, ако съдържа 100 000 стойности и искате да изберете 1 000, тогава всеки 100 000 / 1000 = 100-та стойност ще попадне в извадката. Освен това, ако не са класирани, тогава първият се избира на случаен принцип от първите сто, а числата на останалите ще бъдат със сто повече. Например, ако единица номер 19 е била първата, тогава номер 119 трябва да бъде следващ, след това номер 219, след това номер 319 и т.н. Ако единиците на населението са класирани, тогава първо се избира #50, след това #150, след това #250 и т.н.
- Извършва се избор на стойности от хетерогенен масив от данни стратифицирани(стратифициран) начин, когато генералната съвкупност предварително е разделена на хомогенни групи, към които се прилага случаен или механичен подбор.
- Специален метод за вземане на проби е сериенселекция, при която произволно или механично се избират не отделни количества, а техни серии (поредици от някакво число до някакво последователно), в рамките на които се извършва непрекъснато наблюдение.
Качеството на извадковите наблюдения също зависи от тип вземане на проби: повтореноили неповтарящи се.
В повторен подборстатистическите стойности или техните серии, попаднали в извадката, се връщат в общата съвкупност след употреба, като има шанс да попаднат в нова извадка. В същото време всички стойности на общата съвкупност имат еднаква вероятност да бъдат включени в извадката.
Неповтарящ се изборозначава, че статистическите стойности или техните серии, включени в извадката, не се връщат в общата съвкупност след употреба и следователно вероятността за попадане в следващата извадка се увеличава за останалите стойности на последната.
Неповтарящото се вземане на проби дава по-точни резултати, така че се използва по-често. Но има ситуации, когато не може да се приложи (проучване на пътническите потоци, потребителското търсене и т.н.) и след това се извършва повторен подбор.
Граничната грешка на извадката за наблюдение, средната грешка на извадката, реда, в който са изчислени.
Нека разгледаме подробно горните методи за формиране на извадкова съвкупност и грешките, които възникват в този случай. представителност .
Всъщност - произволноизвадката се основава на подбор на единици от общата съвкупност на случаен принцип без никакви елементи на последователност. Технически правилният произволен избор се извършва чрез теглене на жребий (например лотарии) или чрез таблица с произволни числа.
Всъщност произволната селекция "в чист вид" в практиката на селективното наблюдение се използва рядко, но е първоначалната сред другите видове селекция, която реализира основните принципи на селективното наблюдение. Нека разгледаме някои въпроси от теорията на метода на извадката и формулата за грешка за обикновена произволна извадка.
Грешка при вземане на проби- това е разликата между стойността на параметъра в генералната съвкупност и стойността му, изчислена от резултатите от наблюдението на извадката. За средна количествена характеристика грешката на извадката се определя от
Индикаторът се нарича пределна грешка на извадката.
Средната стойност на извадката е случайна променлива, която може да приема различни стойности в зависимост от това кои единици са в извадката. Следователно грешките при извадката също са случайни променливи и могат да приемат различни стойности. Следователно, определете средната стойност на възможните грешки - средна грешка на извадката, което зависи от:
Размер на извадката: колкото по-голямо е числото, толкова по-малка е средната грешка;
Степента на промяна на изследваната черта: колкото по-малка е вариацията на чертата и, следователно, дисперсията, толкова по-малка е средната грешка на извадката.
В произволен повторен изборсредната грешка се изчислява:
.
На практика общата дисперсия не е точно известна, но в теория на вероятноститедоказа това ![]() .
.
Тъй като стойността за достатъчно голямо n е близка до 1, можем да приемем, че . Тогава средната грешка на извадката може да се изчисли:
.
Но в случаи на малка извадка (за n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
В произволно вземане на пробидадените формули се коригират със стойността . Тогава средната грешка при липса на извадка е:  и
и  .
.
Защото винаги е по-малко от , тогава коефициентът () винаги е по-малък от 1. Това означава, че средната грешка при неповтаряща се селекция винаги е по-малка, отколкото при повторна селекция.
Механично вземане на пробисе използва, когато общото население е подредено по някакъв начин (например избирателни списъци по азбучен ред, телефонни номера, номера на къщи, апартаменти). Изборът на единици се извършва на определен интервал, който е равен на реципрочната стойност на процента от извадката. И така, при извадка от 2% се избират всеки 50 единици = 1 / 0,02, с 5%, всеки 1 / 0,05 = 20 единици от общата съвкупност.
Началото се избира по различни начини: произволно, от средата на интервала, с промяна в началото. Основното нещо е да се избягват системни грешки. Например при 5% проба, ако 13-та е избрана като първа единица, то следващите 33, 53, 73 и т.н.
По отношение на точността механичният подбор е близо до правилното произволно вземане на проби. Следователно, за да се определи средната грешка на механичното вземане на проби, се използват формули за правилен случаен избор.
В типичен избор изследваната популация предварително се разделя на хомогенни, еднотипни групи. Например при анкетиране на предприятия това могат да бъдат отрасли, подсектори, докато се изследва населението – области, социални или възрастови групи. След това се прави независима селекция от всяка група по механичен или правилно произволен начин.
Типичното вземане на проби дава по-точни резултати от другите методи. Типизацията на генералната съвкупност осигурява представянето на всяка типологична група в извадката, което дава възможност да се изключи влиянието на междугруповата дисперсия върху средната грешка на извадката. Следователно, при намиране на грешката на типична извадка според правилото за добавяне на дисперсии (), е необходимо да се вземе предвид само средната стойност на груповите дисперсии. Тогава средната грешка на извадката е:
при повторен подбор
,
с еднократна селекция  ,
,
където  е средната стойност на вътрешногруповите дисперсии в извадката.
е средната стойност на вътрешногруповите дисперсии в извадката.
Сериен (или вложен) избор
използва се, когато съвкупността е разделена на серии или групи преди началото на извадковото изследване. Тези серии могат да бъдат пакети от готови продукти, студентски групи, екипи. Серии за изследване се избират механично или произволно, като в рамките на серията се извършва цялостно изследване на единици. Следователно средната грешка на извадката зависи само от междугруповата (межсерийната) дисперсия, която се изчислява по формулата: 
където r е броят на избраните серии;
- средната стойност на i-та серия.
Средната грешка на серийната извадка се изчислява:
при повторно избиране:
,
с еднократна селекция:  ,
,
където R е общият брой на сериите.
Комбиниранизборе комбинация от разглежданите методи за подбор.
Средната грешка на извадката за всеки метод на подбор зависи главно от абсолютния размер на извадката и в по-малка степен от процента на извадката. Да предположим, че в първия случай са направени 225 наблюдения от популация от 4500 единици, а във втория случай от 225 000 единици. Отклоненията и в двата случая са равни на 25. Тогава, в първия случай, при избор от 5%, грешката на извадката ще бъде: 
Във втория случай, при избор от 0,1%, той ще бъде равен на:

По този начин, с намаляване на процента на извадката с 50 пъти, грешката на извадката се увеличава леко, тъй като размерът на извадката не се променя.
Да приемем, че размерът на извадката е увеличен до 625 наблюдения. В този случай грешката в извадката е: 
Увеличаването на извадката с 2,8 пъти при същия размер на генералната съвкупност намалява размера на грешката на извадката с повече от 1,6 пъти.
Методи и средства за формиране на извадкова съвкупност.
В статистиката се използват различни методи за формиране на извадкови набори, което се определя от целите на изследването и зависи от спецификата на обекта на изследване.
Основното условие за провеждане на извадково изследване е да се предотврати възникването на системни грешки, произтичащи от нарушаването на принципа на равните възможности на всяка единица от генералната съвкупност да влезе в извадката. Предотвратяването на системни грешки се постига в резултат на използването на научно обосновани методи за формиране на извадкова съвкупност.
Има следните начини за избор на единици от общата съвкупност:
1) индивидуален подбор - в извадката се избират отделни единици;
2) групов подбор - в извадката попадат качествено хомогенни групи или серии от изследвани единици;
3) комбинираният подбор е комбинация от индивидуален и групов подбор.
Методите за подбор се определят от правилата за формиране на извадковата съвкупност.
Пробата може да бъде:
- правилно произволносе състои в това, че извадката се формира в резултат на случаен (неволен) подбор на отделни единици от генералната съвкупност. В този случай броят на единиците, избрани в набора от извадки, обикновено се определя въз основа на приетата пропорция от извадката. Делът на извадката е съотношението на броя на единиците в извадковата съвкупност n към броя на единиците в генералната съвкупност N, т.е.
- механиченсе състои в това, че подборът на единици в извадката се извършва от генералната съвкупност, разделена на равни интервали (групи). В този случай размерът на интервала в общата съвкупност е равен на реципрочната част на извадката. Така че при 2% проба се избира всяка 50-та единица (1:0,02), при 5% проба всяка 20-та единица (1:0,05) и т.н. По този начин, в съответствие с приетата пропорция на подбора, генералната съвкупност е като че ли механично разделена на равни групи. От всяка група в извадката се избира само една единица.
- типичен -при което генералната съвкупност първо се разделя на хомогенни типични групи. След това от всяка типична група се прави индивидуален избор на единици в извадката чрез произволна или механична извадка. Важна характеристика на типичната извадка е, че тя дава по-точни резултати в сравнение с други методи за подбор на единици в извадката;
- сериен- при които генералната съвкупност е разделена на групи с еднакъв размер - серии. Сериите са избрани в набора от проби. В рамките на серията се извършва непрекъснато наблюдение на единиците, попаднали в серията;
- комбинирани- вземането на проби може да бъде двуетапно. В този случай общото население първо се разделя на групи. След това се избират групите, а в рамките на последните се избират отделни единици.
В статистиката се разграничават следните методи за избор на единици в извадка::
- единичен етаппроба - всяка избрана единица веднага се подлага на изследване на дадена база (всъщност случайни и серийни проби);
- многостепеннаизвадка – подборът се извършва от генералната съвкупност на отделните групи, а отделните единици се избират от групите (типична извадка с механичен метод за подбор на единици в извадковата съвкупност).
Освен това има:
- повторен избор- по схемата на върнатата топка. В този случай всяка единица или серия, попаднали в извадката, се връщат в генералната съвкупност и следователно има шанс да бъдат включени отново в извадката;
- неповтаряща се селекция- по схемата на невърната топка. Той има по-точни резултати за същия размер на извадката.
Определяне на необходимия размер на извадката (с помощта на таблицата на Студент).
Един от научните принципи в теорията на извадката е да се гарантира, че е избран достатъчен брой единици. Теоретично необходимостта от спазване на този принцип е представена в доказателствата на пределните теореми на теорията на вероятностите, които ви позволяват да установите колко единици трябва да бъдат избрани от общата съвкупност, така че да е достатъчно и да гарантира представителността на извадката.
Намаляването на стандартната грешка на извадката и следователно увеличаването на точността на оценката винаги е свързано с увеличаване на размера на извадката, следователно, още на етапа на организиране на наблюдение на извадката, е необходимо да се реши какъв трябва да бъде размерът на извадката, за да се осигури необходимата точност на резултатите от наблюдението. Изчисляването на необходимия размер на извадката се изгражда с помощта на формули, извлечени от формулите за пределните извадкови грешки (А), съответстващи на един или друг вид и метод на подбор. И така, за произволен повторен размер на извадката (n), имаме:

Същността на тази формула е, че при произволен повторен избор на необходимия брой, размерът на извадката е право пропорционален на квадрата на коефициента на доверие (t2)и дисперсия на вариационния признак (?2) и е обратно пропорционална на квадрата на пределната грешка на извадката (?2). По-специално, чрез удвояване на пределната грешка, необходимият размер на извадката може да бъде намален с коефициент четири. От трите параметъра два (t и?) се задават от изследователя.
В същото време изследователятЗа целите на извадковото изследване следва да се реши въпросът: в каква количествена комбинация е по-добре да се включат тези параметри, за да се осигури оптимален вариант? В единия случай той може да бъде по-доволен от надеждността на получените резултати (t), отколкото от мярката за точност (?), в другия - обратно. По-трудно е да се разреши въпросът относно стойността на пределната грешка на извадката, тъй като изследователят няма този индикатор на етапа на проектиране на извадково наблюдение, следователно на практика е обичайно да се задава пределната грешка на извадката, т.к. правило, в рамките на 10% от очакваното средно ниво на чертата. Установяването на предполагаемо средно ниво може да се подхожда по различни начини: като се използват данни от подобни по-ранни проучвания или се използват данни от рамката на извадката и се взема малка пилотна извадка.
Най-трудното за установяване при проектиране на извадково наблюдение е третият параметър във формула (5.2) – дисперсията на извадковата съвкупност. В този случай е необходимо да се използва цялата информация, с която разполага изследователят, получена от предишни подобни и пилотни проучвания.
Въпрос на дефиницияНеобходимият размер на извадката става по-сложен, ако извадковото изследване включва изследване на няколко характеристики на извадковите единици. В този случай средните нива на всяка от характеристиките и тяхната вариация по правило са различни и следователно е възможно да се реши коя дисперсия на коя от характеристиките да се даде предимство само като се вземат предвид целта и целите на проучването.
При проектирането на извадково наблюдение се приема предварително определена стойност на допустимата грешка на извадката в съответствие с целите на конкретно изследване и вероятността за заключения въз основа на резултатите от наблюдението.
Като цяло, формулата за пределната грешка на средната стойност на извадката ви позволява да определите:
Големината на възможните отклонения на показателите на генералната съвкупност от показателите на извадковата съвкупност;
Необходимият размер на извадката, осигуряващ необходимата точност, при която границите на възможна грешка няма да надвишават определена определена стойност;
Вероятността грешката в извадката да има определена граница.
Разпределение на ученицитев теорията на вероятностите, това е еднопараметърно семейство от абсолютно непрекъснати разпределения.
Поредица от динамика (интервал, момент), затваряне на серии от динамика.
Поредица от динамика- това са стойностите на статистическите показатели, които са представени в определена хронологична последователност.
Всеки времеви ред съдържа два компонента:
1) показатели за периоди от време (години, тримесечия, месеци, дни или дати);
2) показатели, характеризиращи изследвания обект за периоди от време или на съответните дати, които се наричат нива на поредицата.
Нивата на поредицата са изразеникакто абсолютни, така и средни или относителни стойности. В зависимост от естеството на показателите се изграждат динамични серии от абсолютни, относителни и средни стойности. Динамичните серии от относителни и средни стойности се изграждат на базата на производни серии от абсолютни стойности. Има интервални и моментни серии от динамика.
Динамични интервални сериисъдържа стойностите на индикаторите за определени периоди от време. В интервалната серия нивата могат да се сумират, като се получава обемът на явлението за по-дълъг период или така наречените натрупани суми.
Серия с динамични моментиотразява стойностите на индикаторите в определен момент от време (дата на времето). В моментните серии изследователят може да се интересува само от разликата на явленията, отразяваща промяната в нивото на поредицата между определени дати, тъй като сборът от нивата тук няма реално съдържание. Кумулативните суми не се изчисляват тук.
Най-важното условие за правилното изграждане на динамичните редове е съпоставимостта на нивата на редовете, отнасящи се до различни периоди. Нивата трябва да бъдат представени в хомогенни количества, трябва да има еднаква пълнота на обхващане на различни части на явлението.
Да сеЗа да се избегне изкривяване на реалната динамика, се извършват предварителни изчисления в статистическото изследване (затваряне на динамиката), които предхождат статистическия анализ на динамичния ред. Под затваряне на времеви редове се разбира обединяването на две или повече серии в една серия, чиито нива се изчисляват по различна методология или не отговарят на териториални граници и т.н. Затварянето на поредицата от динамика може да предполага и редуциране на абсолютните нива на поредицата от динамика до обща основа, което елиминира несъвместимостта на нивата на поредицата от динамика.
Концепцията за съпоставимост на времеви редове, коефициенти, растеж и темпове на растеж.
Поредица от динамика- това са поредици от статистически показатели, характеризиращи развитието на природните и социални явления във времето. Статистическите колекции, публикувани от Държавния статистически комитет на Русия, съдържат голям брой времеви серии в табличен вид. Поредица от динамика позволява да се разкрият закономерностите на развитие на изследваните явления.
Динамичните редове съдържат два вида индикатори. Индикатори за време(години, тримесечия, месеци и т.н.) или точки във времето (в началото на годината, в началото на всеки месец и т.н.). Индикатори на ниво ред. Индикаторите на нивата на времевите редове могат да бъдат изразени в абсолютни стойности (производство в тонове или рубли), относителни стойности (дял на градското население в%) и средни стойности (средни заплати на работниците в индустрията по години, и др.). В табличен вид времевият ред съдържа две колони или два реда.
Правилното изграждане на времеви редове включва изпълнението на редица изисквания:
- всички показатели на поредица от динамика трябва да бъдат научно обосновани, надеждни;
- показателите на поредица от динамика трябва да бъдат съпоставими във времето, т.е. трябва да се изчисляват за едни и същи периоди от време или на същите дати;
- индикаторите за редица динамики трябва да бъдат сравними в цялата територия;
- индикаторите на поредица от динамика трябва да бъдат съпоставими по съдържание, т.е. изчислява се по една и съща методика;
- индикаторите на поредица от динамика трябва да бъдат сравними за всички разглеждани стопанства. Всички показатели на серия от динамика трябва да бъдат дадени в едни и същи мерни единици.
Статистически показателиможе да характеризира или резултатите от изследвания процес за определен период от време, или състоянието на изследваното явление в определен момент от време, т.е. индикаторите могат да бъдат интервални (периодични) и моментни. Съответно, първоначално поредицата от динамика може да бъде или интервална, или моментна. Моментната поредица от динамика от своя страна може да бъде с равни и неравни интервали от време.
Първоначалната серия от динамика може да бъде преобразувана в серия от средни стойности и серия от относителни стойности (верига и база). Такива времеви редове се наричат извлечени времеви редове.
Методът за изчисляване на средното ниво в серията от динамика е различен, поради вида на сериите от динамика. Използвайки примери, разгледайте видовете времеви редове и формулите за изчисляване на средното ниво.
Абсолютни печалби (Δy) показва колко единици се е променило следващото ниво на поредицата спрямо предишното (колона 3. - верижни абсолютни приращения) или спрямо първоначалното ниво (колона 4. - основни абсолютни приращения). Формулите за изчисление могат да бъдат написани, както следва:

С намаляване на абсолютните стойности на серията ще има съответно "намаляване", "намаляване".
Показателите за абсолютен ръст сочат, че например през 1998 г. производството на продукт "А" нараства с 4000 тона спрямо 1997 г. и с 34 000 тона спрямо 1994 г.; за други години вижте таблицата. 11,5 гр. 3 и 4.
Фактор на растежпоказва колко пъти нивото на поредицата се е променило спрямо предишното (колона 5 - верижни коефициенти на растеж или спад) или спрямо първоначалното ниво (колона 6 - основни коефициенти на растеж или спад). Формулите за изчисление могат да бъдат написани, както следва:

Темпи на растежпоказват колко процента е следващото ниво от поредицата в сравнение с предишното (колона 7 - темпове на растеж на веригата) или в сравнение с първоначалното ниво (колона 8 - основни темпове на растеж). Формулите за изчисление могат да бъдат написани, както следва:

Така например през 1997 г. обемът на производството на продукт "А" в сравнение с 1996 г. е 105,5% (
Темпове на растежпоказват с колко процента се е увеличило нивото на отчетния период спрямо предишния (колона 9 - верижни темпове на растеж) или спрямо първоначалното ниво (колона 10 - основни темпове на растеж). Формулите за изчисление могат да бъдат написани, както следва:
T pr = T p - 100% или T pr = абсолютно увеличение / ниво от предходния период * 100%
Така например през 1996 г. в сравнение с 1995 г. продуктът "А" е произведен повече с 3,8% (103,8% - 100%) или (8:210) x 100%, а в сравнение с 1994 г. - с 9% ( 109% - 100%).
Ако абсолютните нива в серията намалеят, тогава скоростта ще бъде по-малка от 100% и съответно ще има темп на спад (темп на растеж със знак минус).
Абсолютна стойност от 1% увеличение(колона 11) показва колко единици трябва да бъдат произведени за даден период, за да се увеличи нивото от предходния период с 1%. В нашия пример през 1995 г. е необходимо да се произведат 2,0 хил. тона, а през 1998 г. - 2,3 хил. тона, т.е. много по-голям.
Има два начина за определяне на величината на абсолютната стойност на 1% растеж:
Разделете нивото от предходния период на 100;
Разделете абсолютните темпове на растеж на веригата на съответните темпове на растеж на веригата.
Абсолютна стойност от 1% увеличение = 
В динамиката, особено за дълъг период от време, е важно съвместно да се анализира темпът на растеж със съдържанието на всеки процент увеличение или намаление.
Имайте предвид, че разглежданият метод за анализ на времеви редове е приложим както за времеви редове, чиито нива са изразени в абсолютни стойности (t, хиляди рубли, брой служители и т.н.), така и за времеви редове, нивата на които се изразяват в относителни показатели (% скрап, % пепел във въглищата и др.) или средни стойности (среден добив в c/ha, средна заплата и др.).
Наред с разглежданите аналитични показатели, изчислени за всяка година в сравнение с предишното или първоначалното ниво, при анализа на времевите редове е необходимо да се изчислят средните аналитични показатели за периода: средното ниво на серията, средното годишно абсолютно увеличение (намаляване) и средния годишен темп на растеж и темп на растеж.
Методите за изчисляване на средното ниво на серия от динамика бяха обсъдени по-горе. В интервалната серия от динамика, която разглеждаме, средното ниво на серията се изчислява по простата формула на средната аритметична:
Средногодишното производство на продукта за 1994-1998г. възлиза на 218,4 хил. тона.
Средното годишно абсолютно увеличение също се изчислява по формулата на простата средна аритметична стойност:
Годишните абсолютни прирасти варират през годините от 4 до 12 хил. тона (виж гр. 3), а средногодишното увеличение на производството за периода 1995 - 1998 г. възлиза на 8,5 хиляди тона.
Методите за изчисляване на средния темп на растеж и средния темп на растеж изискват по-подробно разглеждане. Нека ги разгледаме на примера на годишните показатели на серийното ниво, дадени в таблицата.
Средното ниво на диапазона на динамиката.
Серия от динамика (или времеви серии)- това са числовите стойности на определен статистически индикатор в последователни моменти или периоди от време (т.е. подредени в хронологичен ред).
Наричат се числените стойности на конкретен статистически индикатор, който съставя поредица от динамика нива на числои обикновено се обозначава с буквата г. Първи член на поредицата y 1наречен начален или изходна линия, и последното y n - финал. Моментите или периодите от време, за които се отнасят нивата, се означават с T.
Динамичните серии, като правило, се представят под формата на таблица или графика, а времевата скала се изгражда по оста x T, а по ординатата - скалата на нивата на поредицата г.
Средни показатели на серия от динамика
Всяка серия от динамика може да се разглежда като определен набор нвариращи във времето показатели, които могат да се обобщят като средни стойности. Такива обобщени (средни) показатели са особено необходими при сравняване на промените в един или друг показател през различни периоди, в различни държави и т.н.
Обобщена характеристика на поредица от динамика може да бъде преди всичко, средно ниво на ред. Методът за изчисляване на средното ниво зависи от това дали е моментна серия или интервална (периодна) серия.
Кога интервалсерия, нейното средно ниво се определя по формулата на проста средноаритметична стойност на нивата на серията, т.е.
=
Ако е налична моментред, съдържащ ннива ( y1, y2, …, yn) с равни интервали между датите (моменти от време), тогава такава серия може лесно да се преобразува в серия от средни стойности. В същото време индикаторът (нивото) в началото на всеки период е едновременно индикатор в края на предходния период. Тогава средната стойност на индикатора за всеки период (интервал между датите) може да се изчисли като полусума от стойностите прив началото и в края на периода, т.е. как . Броят на тези средни стойности ще бъде . Както бе споменато по-рано, за серии от средни стойности, средното ниво се изчислява от средната аритметична стойност.
Следователно можем да напишем: .
.
След преобразуване на числителя получаваме: ,
,
където Y1и Yn- първото и последното ниво на поредицата; Yi- междинни нива.
Тази средна стойност е известна в статистиката като средно хронологичноза моментна серия. Тя получи това име от думата "cronos" (време, лат.), тъй като се изчислява от показатели, които се променят с времето.
При неравностойноинтервали между датите, хронологичната средна за моментната поредица може да се изчисли като средноаритметично от средните стойности на нивата за всяка двойка моменти, претеглени от разстоянията (интервали от време) между датите, т.е.  .
.
В такъв случайприема се, че в интервалите между датите нивата са придобили различни стойности, а ние сме от две известни ( йии yi+1) определяме средните стойности, от които след това изчисляваме общата средна стойност за целия анализиран период.
Ако се приеме, че всяка стойност йиостава непроменен до следващия (i+ 1)-
този момент, т.е. точната дата на промяната в нивата е известна, тогава изчислението може да се извърши с помощта на претеглената средноаритметична формула:
,
където е времето, през което нивото е останало непроменено.
В допълнение към средното ниво в серията от динамика се изчисляват и други средни показатели - средната промяна в нивата на серията (основни и верижни методи), средната скорост на изменение.
Изходното ниво означава абсолютна промянае частното от последната основна абсолютна промяна, разделено на броя на промените. Това е
Верига означава абсолютна промяна нива на серия е частното от разделянето на сумата от всички абсолютни промени във веригата на броя на промените, т.е.
По знака на средните абсолютни промени се оценява и естеството на изменението на явлението средно: растеж, спад или стабилност.
От правилото за контролиране на основни и верижни абсолютни промени следва, че основните и верижните средни промени трябва да са равни.
Наред със средната абсолютна промяна, средната относителна се изчислява и чрез основния и верижния методи.
Изходна средна относителна промянасе определя по формулата:
Верига означава относителна промянасе определя по формулата:
Естествено, основните и верижните средни относителни промени трябва да са еднакви и като се съпоставят със стойността на критерия 1, се прави извод за естеството на промяната на явлението средно: растеж, спад или стабилност.
Чрез изваждане на 1 от средната относителна промяна на базата или веригата се получава съответното среден темп на промяна, по чийто признак може да се съди и за характера на изменението на изследваното явление, отразено от тази поредица от динамика.
Сезонни колебания и индекси на сезонност.
Сезонните колебания са стабилни вътрешногодишни колебания.
Основният принцип за постигане на максимален ефект е максимизиране на приходите и минимизиране на разходите. Чрез изучаване на сезонните колебания се решава проблемът за максималното уравнение на всяко ниво от годината.
При изучаване на сезонните колебания се решават две взаимосвързани задачи:
1. Идентифициране на спецификата на развитието на явлението във вътрешногодишна динамика;
2. Измерване на сезонните колебания с изграждане на сезонен вълнов модел;
Сезонните пуйки обикновено се броят за измерване на сезонността. Най-общо те се определят от съотношението на оригиналните уравнения на поредица от динамика към теоретичните уравнения, които служат като основа за сравнение.
Тъй като случайните отклонения се наслагват върху сезонните колебания, индексите на сезонността се осредняват, за да ги елиминират.
В този случай за всеки период от годишния цикъл се определят обобщените показатели под формата на средни сезонни индекси:
Средните индекси на сезонните колебания са освободени от влиянието на случайни отклонения на основната тенденция на развитие.
В зависимост от естеството на тенденцията, формулата за средния индекс на сезонност може да приеме следните форми:
1.За серии от вътрешногодишна динамика с ясно изразена основна тенденция на развитие:
2. За поредицата от вътрешногодишна динамика, при която няма възходяща или низходяща тенденция или е незначителна:
Къде е общата средна стойност;
Методи за анализ на основната тенденция.
Развитието на явленията във времето се влияе от различни по характер и сила на влияние фактори. Някои от тях имат произволен характер, други имат почти постоянен ефект и формират определена тенденция на развитие в поредицата от динамика.
Важна задача на статистиката е да идентифицира тенденция в поредицата от динамика, освободена от действието на различни случайни фактори. За целта времевите редове се обработват по методите на интервално уголемяване, плъзгаща средна и аналитично изравняване и др.
Метод на интервално загрубяванесе основава на разширяване на периоди от време, които включват нивата на поредица от динамика, т.е. е замяната на данни, свързани с малки периоди от време, с данни от по-големи периоди. Особено ефективен е, когато началните нива на серията са за кратки периоди от време. Например, сериите от индикатори, свързани с ежедневни събития, се заменят със серии, свързани със седмични, месечни и т.н. Това ще покаже по-ясно "Ос на развитие на феномена". Средната стойност, изчислена на базата на увеличени интервали, дава възможност да се идентифицира посоката и характера (ускоряване или забавяне на растежа) на основната тенденция на развитие.
метод на плъзгаща се среднаподобен на предишния, но в този случай действителните нива се заменят със средни нива, изчислени за последователно движещи се (плъзгащи се) увеличени интервали, покриващи мнива на редове.
Напримерако се приеме m=3,след това първо се изчислява средната стойност на първите три нива от серията, след това - от същия брой нива, но започвайки от второто поред, след това - започвайки от третото и т.н. По този начин средната стойност сякаш се "плъзга" по поредицата от динамика, движейки се за един период. Изчислено от мчленовете на подвижните средни се отнасят до средата (центъра) на всеки интервал.
Този метод елиминира само случайни колебания. Ако поредицата има сезонна вълна, тя ще остане след изглаждане по метода на пълзящата средна.
Аналитично подравняване. За да се елиминират произволни колебания и да се идентифицира тенденция, нивата на серията се подравняват според аналитични формули (или аналитично подравняване). Същността му е да замени емпиричните (действителни) нива с теоретични, които се изчисляват по определено уравнение, взето като математически модел на тенденцията, където теоретичните нива се разглеждат като функция на времето: . В този случай всяко действително ниво се разглежда като сбор от два компонента: , където е систематичен компонент и се изразява с определено уравнение и е случайна променлива, която причинява колебания около тренда.
Задачата на аналитичното подравняване е, както следва:
1. Определяне на базата на действителни данни вида на хипотетична функция, която може най-адекватно да отрази тенденцията на развитие на изследвания индикатор.
2. Намиране на параметрите на посочената функция (уравнение) от емпирични данни
3. Изчисляване по намереното уравнение на теоретичните (нивелирани) нива.
Изборът на определена функция по правило се извършва въз основа на графично представяне на емпирични данни.
Моделите са регресионни уравнения, чиито параметри се изчисляват по метода на най-малките квадрати
По-долу са най-често използваните регресионни уравнения за изравняване на времеви редове, посочващи кои тенденции на развитие са най-подходящи за отразяване.
За намиране на параметрите на горните уравнения има специални алгоритми и компютърни програми. По-специално, за да се намерят параметрите на уравнението на права линия, може да се използва следният алгоритъм:

Ако периодите или моментите от време се номерират така, че да се получи St = 0, тогава горните алгоритми ще бъдат значително опростени и ще се превърнат в

Подравнените нива на графиката ще бъдат разположени на една права линия, минаваща на най-близкото разстояние от действителните нива на тази динамична серия. Сборът от квадратите отклонения е отражение на влиянието на случайни фактори.
С негова помощ изчисляваме средната (стандартна) грешка на уравнението:

Тук n е броят на наблюденията, а m е броят на параметрите в уравнението (имаме два от тях - b 1 и b 0).
Основният тренд (тренд) показва как систематичните фактори влияят на нивата на времевите редове, а флуктуацията на нивата около тренда () служи като мярка за въздействието на остатъчни фактори.
За да се оцени качеството на използвания модел на времеви ред, той също се използва F тест на Фишер. Това е съотношението на две вариации, а именно съотношението на дисперсията, причинена от регресията, т.е. изследван фактор, до дисперсията, причинена от случайни причини, т.е. остатъчна дисперсия:
![]()
В разширен вид формулата за този критерий може да бъде представена, както следва:
![]()
където n е броят на наблюденията, т.е. брой нива на редове,
m е броят на параметрите в уравнението, y е действителното ниво на серията,
Подравнено ниво на реда, - средното ниво на реда.
По-успешен от другите, моделът може да не винаги е достатъчно задоволителен. Тя може да бъде призната за такава само ако критерият F за нея преминава определена критична граница. Тази граница се задава с помощта на F таблици за разпределение.
Същност и класификация на индексите.
Индексът в статистиката се разбира като относителен индикатор, който характеризира промяната в величината на дадено явление във времето, пространството или в сравнение с всеки стандарт.
Основният елемент на индексната връзка е индексираната стойност. Под индексирана стойност се разбира стойността на признак на статистическа съвкупност, чиято промяна е обект на изследване.
Индексите служат на три основни цели:
1) оценка на промените в комплексно явление;
2) определяне на влиянието на отделните фактори върху изменението на комплексно явление;
3) сравнение на величината на някое явление с величината на миналия период, величината на друга територия, както и със стандарти, планове, прогнози.
Индексите се класифицират по 3 критерия:
2) по степента на обхват на елементите на населението;
3) чрез методи за изчисляване на общи индекси.
По съдържаниена индексирани стойности, индексите се разделят на индекси на количествени (обемни) показатели и индекси на качествени показатели. Индекси на количествените показатели - индекси на физическия обем на промишленото производство, физическия обем на продажбите, броя и др. Индекси на качествените показатели - индекси на цени, разходи, производителност на труда, средна работна заплата и др.
Според степента на обхват на единици от населението индексите се разделят на два класа: индивидуални и общи. За да ги характеризираме, ние въвеждаме следните конвенции, възприети в практиката на прилагане на индексния метод:
q- количество (обем) на всеки продукт в натура ; Р- единична цена на продукцията; z- себестойност на единица продукция; T- време, прекарано за производството на единица продукция (интензивност на труда) ; w- продукция в стойностно изражение за единица време; v- продукция във физическо изражение за единица време; T- общо прекарано време или брой служители.
За да се разграничи към кой период или обект принадлежат индексираните стойности, обичайно е да се поставят индекси след съответния символ в долния десен ъгъл. Така, например, в индексите на динамиката, като правило, за сравняваните (текущи, отчетни) периоди се използва индексът 1, а за периодите, с които се прави сравнението,
Индивидуални индексислужат за характеризиране на промяната в отделни елементи на сложно явление (например промяна в обема на продукцията на един вид продукт). Те представляват относителните стойности на динамиката, изпълнението на задълженията, сравнението на индексираните стойности.
Определя се индивидуалният индекс на физическия обем на продукцията
От аналитична гледна точка дадените индивидуални индекси на динамика са подобни на коефициентите (темпите) на растеж и характеризират изменението на индексираната стойност през текущия период спрямо базовия, тоест показват колко пъти се е увеличила (намаляла) ) или колко процента е растеж (намаляване). Стойностите на индекса се изразяват в коефициенти или проценти.
Общ (съставен) индексотразява промяната във всички елементи на едно сложно явление.
Агрегиран индексе основната форма на индекса. Нарича се съвкупност, защото неговият числител и знаменател са набор от "агрегат"
Средни индекси, тяхното определение.
Освен агрегираните индекси в статистиката се използва и друга форма от тях - среднопретеглени индекси. Към тяхното изчисляване се прибягва, когато наличната информация не позволява да се изчисли общият агрегиран индекс. Така че, ако няма данни за цените, но има информация за себестойността на продуктите в текущия период и са известни индивидуални ценови индекси за всеки продукт, тогава общият индекс на цените не може да се определи като съвкупен, но е възможно да го изчислим като средна стойност от отделните. По същия начин, ако количествата на отделните произведени продукти не са известни, но са известни индивидуалните индекси и производствените разходи за базовия период, тогава общият индекс на физическия обем на производството може да се определи като среднопретеглена.
Среден индекс -това еиндекс, изчислен като средна стойност на отделните индекси. Агрегираният индекс е основната форма на общия индекс, така че средният индекс трябва да бъде идентичен с агрегирания индекс. При изчисляване на средните индекси се използват две форми на средни стойности: аритметична и хармонична.
Средноаритметичният индекс е идентичен с агрегирания индекс, ако теглата на отделните индекси са членовете на знаменателя на агрегатния индекс. Само в този случай стойността на индекса, изчислена по средноаритметичната формула, ще бъде равна на обобщения индекс.
Програмата Excel е високо оценена както от професионалисти, така и от аматьори, тъй като потребител на всякакво ниво на обучение може да работи с нея. Например всеки с минимални умения за „комуникация“ с Excel може да нарисува обикновена графика, да направи приличен знак и т.н.
В същото време тази програма дори ви позволява да извършвате различни видове изчисления, например изчисления, но това вече изисква малко по-различно ниво на обучение. Въпреки това, ако току-що сте започнали отблизо запознаване с тази програма и се интересувате от всичко, което ще ви помогне да станете по-напреднал потребител, тази статия е за вас. Днес ще ви кажа какво представлява формулата за стандартно отклонение в excel, защо изобщо е необходима и всъщност кога се прилага. Отивам!
Какво е
Да започнем с теорията. Стандартното отклонение обикновено се нарича квадратен корен, получен от средната аритметична стойност на всички квадратирани разлики между наличните стойности, както и тяхната средна аритметична стойност. Между другото, тази стойност обикновено се нарича гръцката буква "сигма". Стандартното отклонение се изчислява по формулата STDEV, съответно програмата го прави за самия потребител.
Същността на тази концепция е да се идентифицира степента на променливост на инструмента, тоест той по свой начин е индикатор от дескриптивната статистика. Той разкрива промени във волатилността на инструмента през всеки период от време. Използвайки STDEV формули, можете да оцените стандартното отклонение на извадка, докато булевите и текстовите стойности се игнорират.
Формула
Помага за изчисляване на стандартното отклонение във формулата на Excel, която автоматично се предоставя в Excel. За да го намерите, трябва да намерите раздела за формула в Excel и вече там да изберете този, който има име STDEV, така че е много просто.
След това пред вас ще се появи прозорец, в който ще трябва да въведете данни за изчислението. По-специално, две числа трябва да бъдат въведени в специални полета, след което програмата автоматично ще изчисли стандартното отклонение за извадката.

Несъмнено математическите формули и изчисления са доста сложен въпрос и не всички потребители могат да се справят с него веднага. Ако обаче се поразровите малко и разберете въпроса малко по-подробно, се оказва, че не всичко е толкова тъжно. Надявам се, че сте се убедили в това с примера за изчисляване на стандартното отклонение.
Видео в помощ




